
The idea that serious multimodal AI requires cloud infrastructure is starting to break.
On June 3, Google DeepMind released Gemma 4 12B—an open-weight model that can process text, images, audio, and video locally on devices with around 16GB of memory. That includes the kind of laptops many enterprise employees already use daily.
This isn’t just another model release. It’s a shift in where AI workloads can live—and who controls them.
A Different Approach to Multimodal AI
Most multimodal systems today are built as assemblies:
- A vision encoder for images
- A separate audio encoder
- A language model for reasoning
- An orchestration layer to connect them
That structure works, but it comes with overhead—multiple components to train, maintain, and debug.
Gemma 4 12B takes a different route.
Instead of relying on specialized encoders, it uses a unified decoder-only transformer:
- Images are converted into visual patches and projected into token space
- Audio waveforms follow a similar projection path
- All inputs are processed within the same model
The visual component is reduced to a lightweight ~35M parameter module. The dedicated audio encoder is removed entirely.
The result is a system where multimodal reasoning happens in a single pass—without stitching together separate subsystems.
For engineering teams, that simplification matters. It means:
- One model to fine-tune
- One system to deploy
- Fewer integration failures across modalities
Performance That’s “Close Enough” to Change Behavior
On benchmarks, Gemma 4 12B approaches the performance of larger models, including 26B mixture-of-experts systems, while using significantly less memory. It also improves over previous Gemma releases at similar or larger sizes.
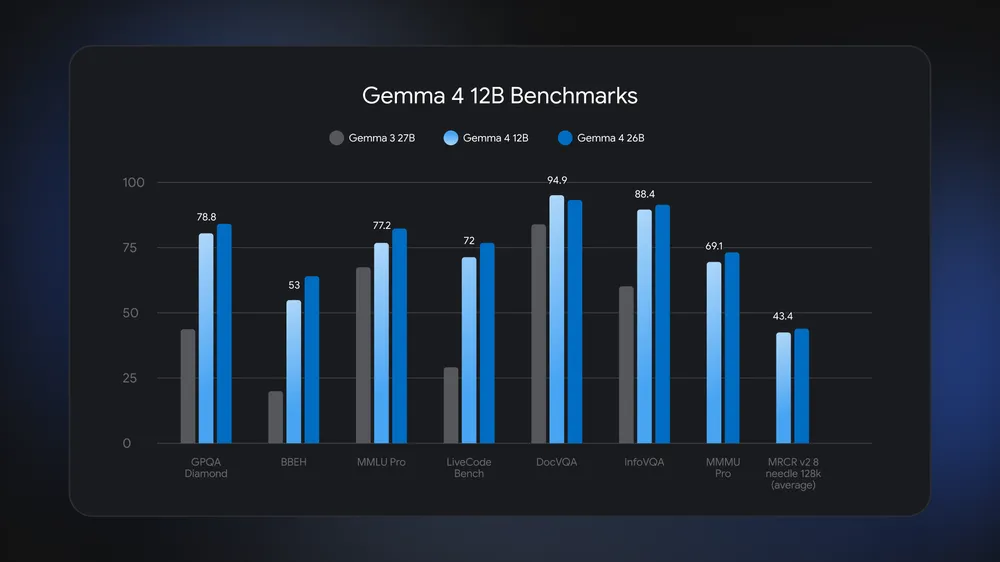
Key capabilities include:
- A 256K token context window
- Built-in Multi-Token Prediction for faster generation
- Native multimodal input handling (text, image, audio, video)
In one demonstration tied to Google I/O, the model processed a five-minute keynote segment using hundreds of video frames alongside synchronized audio—something that previously required multi-model pipelines running in the cloud.
The more important shift isn’t the benchmark score. It’s where the model runs.
Gemma 4 12B is designed to operate on:
- Apple Silicon laptops
- Qualcomm Snapdragon X systems
- Any machine with ~16GB unified memory
That moves multimodal AI from infrastructure to endpoints.
The Real Story: Data Control, Not Just Cost
While local inference reduces cloud costs, the bigger implication is control.
Running multimodal AI locally means:
- Sensitive data never leaves the device
- No external inference logs
- No dependency on third-party processing agreements
For industries dealing with regulated or proprietary data—finance, healthcare, government—this changes what’s possible.
Workflows involving:
- Meeting recordings
- Internal video analysis
- Medical or technical imaging
…can now be executed without sending data to external servers.
With an Apache 2.0 license, the model is also commercially usable without restrictive terms, lowering legal friction for enterprise adoption.
Ecosystem Signals: This Is a Distribution Strategy
The release isn’t just about the model itself.
Google is clearly positioning Gemma 4 12B inside a broader developer ecosystem:
- Support for tools like llama.cpp, MLX, and Unsloth
- A growing repository of “skills” targeting agent-based workflows
- Optimization for local and edge deployment
This suggests a deliberate push: not just to compete in model quality, but to own the edge layer of AI deployment.
Where the Argument Breaks
Despite the advances, Gemma 4 12B is not a full replacement for all multimodal systems.
There are tradeoffs.
By removing specialized encoders, the model simplifies architecture—but may lag in:
- High-precision vision tasks
- Advanced audio understanding
- Benchmark ceilings achieved by specialized pipelines
Competitors using dedicated encoders can still outperform unified systems in certain domains.
That means cloud-based, high-capability stacks are not going away—especially for:
- Large-scale inference
- Ultra-high accuracy requirements
- Complex distributed workflows
What Actually Changes
Gemma 4 12B doesn’t eliminate the cloud.
It changes the default.
Before:
- Local AI handled lightweight tasks
- Multimodal reasoning required cloud infrastructure
Now:
- Most multimodal workflows can run locally
- The cloud becomes optional—not mandatory
That shift has practical consequences.
Teams now have to justify:
- Why does data leave the device
- Why are multiple models required
- Why orchestration complexity exists
Bottom Line
Gemma 4 12B is less about raw capability and more about architecture and placement.
By collapsing multimodal processing into a single model that runs on widely available hardware, Google DeepMind is pushing AI workloads closer to the user—and away from centralized infrastructure.
For companies building multimodal systems, the question is no longer just performance.
It’s whether their existing stack—multiple models, APIs, and cloud dependencies—still justifies its complexity in a world where a single model can handle most of the same work locally.
That’s the real disruption.
Related: How to Run DeepSeek Locally in 2026: Fast, Private & Efficient
