As enterprise spend shifts from experimental AI prototyping to large-scale production, engineering teams face a sharp reality check: the hidden economics of the AI token. Understanding them isn’t optional anymore — it’s what separates teams that control their AI costs from teams that don’t.
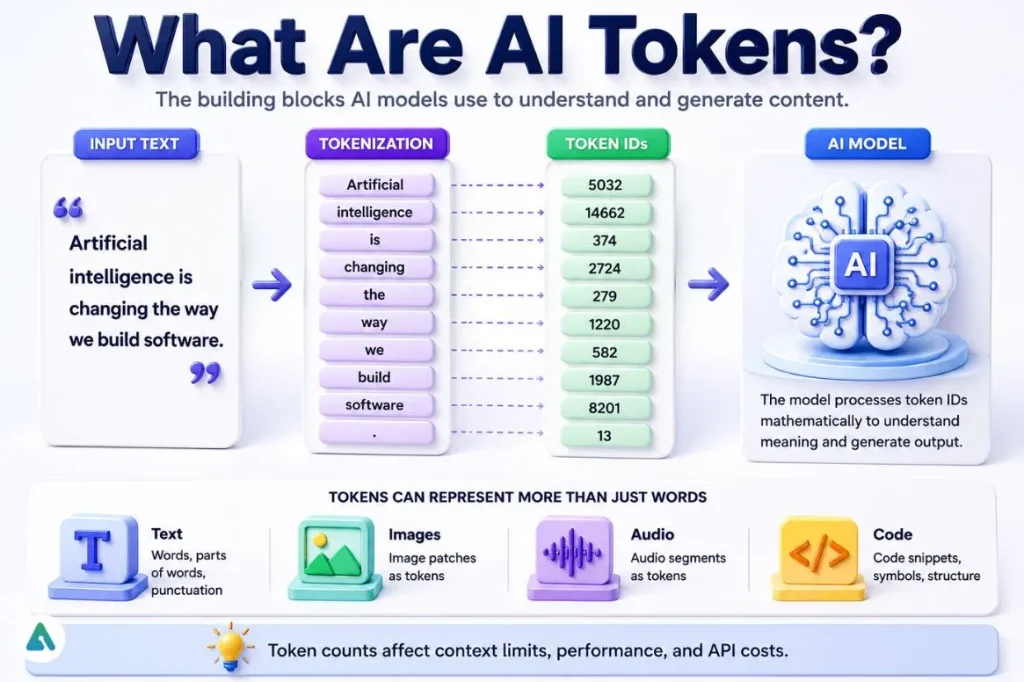
Tokens are the fundamental building blocks of every modern AI system. Before a large language model reads your prompt, generates a response, or processes an image, it first converts everything into tokens.
Token usage determines how much a model remembers, how much each API call costs, and why your bill from AI services looks nothing like you expected. The maximum number of tokens a model handles at once also caps what it can analyze in a single session.
Key Takeaways
|
What a Token Actually Is
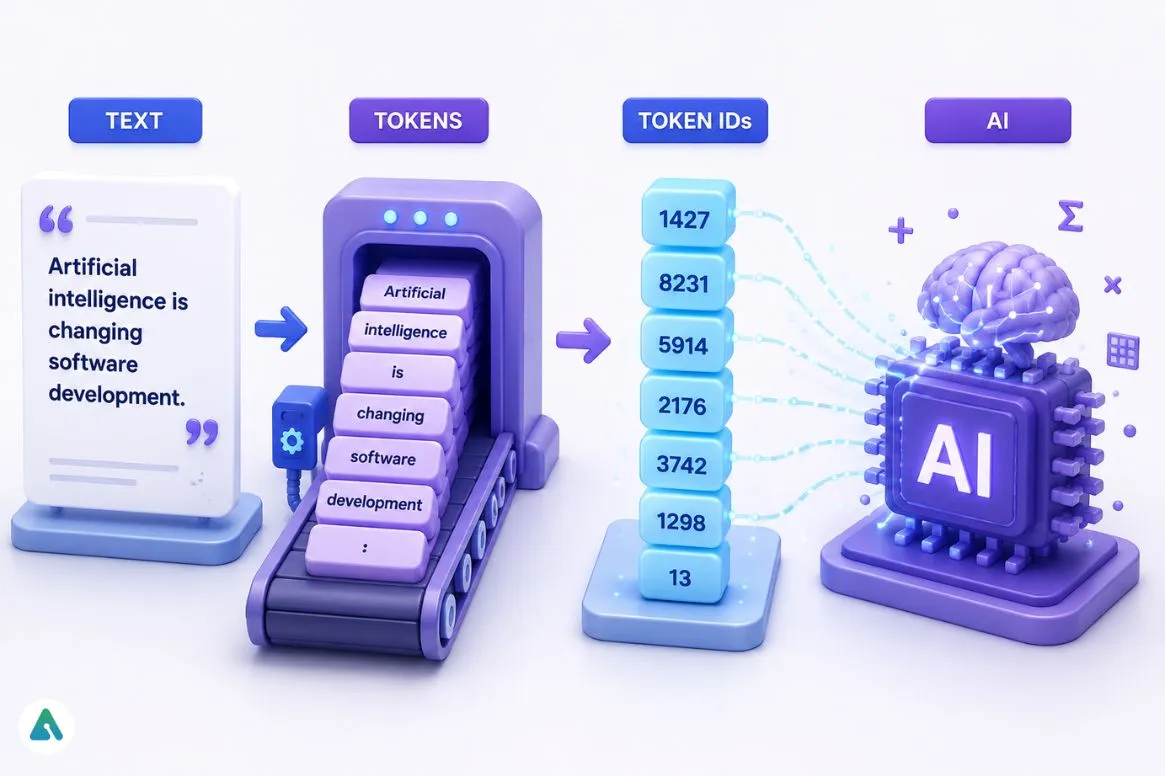
A token is a small chunk of text that a language model processes as a single unit. Not a word, not a character — something in between, and the exact size varies by model and content type.
Take the sentence “Artificial intelligence is changing software development.” A tokenizer splits it into roughly seven pieces — each common word becomes a single token, and the period becomes another. But “internationalization” can fragment into four or five tokens because it’s rare enough that no tokenizer bothers compressing it into one unit.
AI models read numbers, not words. Before any text reaches a large language model, a tokenizer converts it into a list of integer IDs drawn from a vocabulary dictionary:
| Text Fragment | Token ID |
|---|---|
| AI | 1427 |
| model | 8231 |
| intelligence | 5914 |
| software | 2176 |
The model processes those IDs mathematically. It never sees the original words — only their numeric representations. Get tokenization wrong in your application design, and you pay for it in both dollars and output quality.
Why Word-Based Tokenization Fails in Enterprise LLMs
Language is far messier than it looks. A word-based system would need separate handling for Python syntax, markdown, emojis, URLs, equations, and dozens of foreign character sets. That doesn’t scale in production.
Tokenization sidesteps the problem by breaking language into reusable subword fragments. The model isn’t memorizing words — it’s learning statistical patterns between token sequences.
That’s why the same architecture handles code, slang, multiple languages, and technical documentation without needing specialized modules for each content type. Tokens are the building blocks that make general-purpose AI services possible across every language and format.
How Byte-Pair Encoding Builds the Vocabulary Dictionary
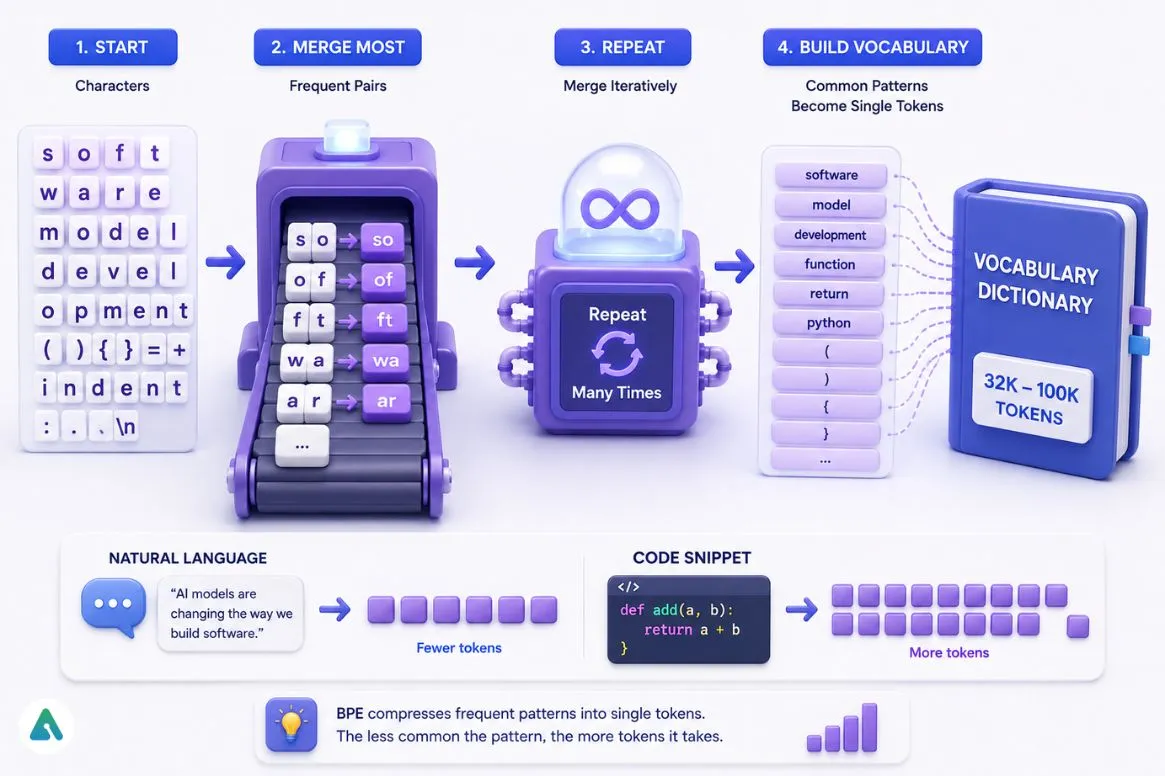
Modern AI models use a compression technique called Byte-Pair Encoding (BPE) — shorthand for machines.
BPE starts by treating every character as its own token. It then scans the entire training corpus and repeatedly merges the most frequently co-occurring pairs into single units via character-level merging. After enough iterations, common words like “software” or “model” each compress into a single token.
The result is a vocabulary of 32,000 to 100,000 entries where frequent patterns compress efficiently, and unusual content costs more token counts per character. This is why a Python function that looks shorter than a paragraph of prose can generate more tokens: curly braces, indentation, parentheses, and operators all become separate entries that don’t compress the way natural language does.
OpenAI’s interactive tokenizer tool lets you paste any text and watch this fragmentation happen in real time — the fastest way to build intuition for why token counts rarely match word counts.
From Numbers to Meaning: How Token IDs Become Vectors
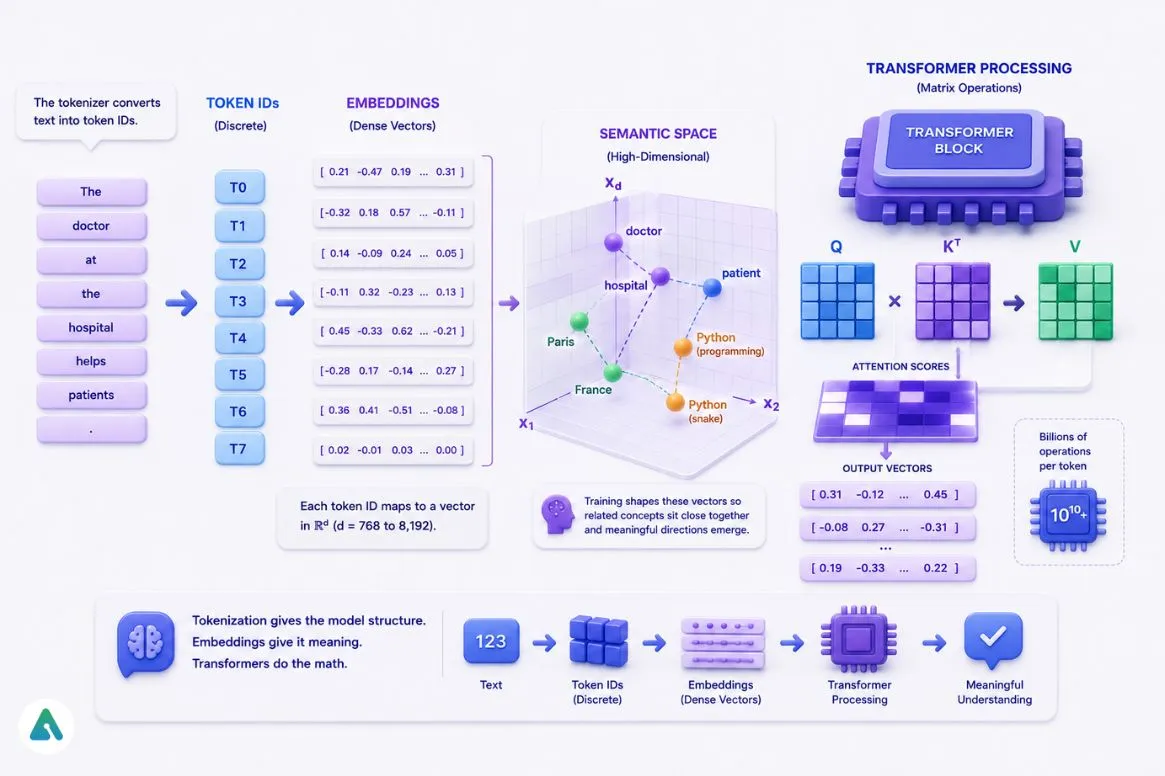
Tokenization converts text into IDs. That’s the entry point — but not where understanding happens.
What the model actually processes are embeddings: high-dimensional mathematical vectors derived from those IDs. Each token ID maps to a vector in a space with hundreds or thousands of dimensions.
More precisely: the tokenizer maps a sequence of discrete token IDs T=(t1,t2,…,tn)T = (t_1, t_2, \dots, t_n) to a sequence of dense continuous vectors E=(e1,e2,…,en)E = (e_1, e_2, \dots, e_n) , where each embedding vector ei∈Rde_i \in \mathbb{R}^d represents a point in a high-dimensional space encoding latent semantic meaning. The dimension dd typically ranges from 768 to 8,192, depending on model size — larger models use wider vectors to capture finer conceptual distinctions.
Through training, the model learns that “doctor” and “hospital” sit close together in that space, that “Paris” and “France” relate in a specific directional way, and that “Python” clusters with programming rather than wildlife. Anthropic’s research into Claude’s internal vector states offers a concrete look at how these representations behave inside a production model.
Under the hood, the transformer architecture runs enormous matrix multiplications across these vectors — billions of operations per token for large models.
Token Limits and What They Actually Cost
When one engineering team migrated a legacy agent loop to a new orchestration framework last quarter, their testing environment burned through an entire month’s API budget in three hours. The culprit wasn’t an infinite loop — it was an unoptimized system prompt bloating the token overhead on every single iteration.
A 100-page PDF analysis consumes roughly 40,000 input tokens without caching. At standard 2026 API rates on a premium model, that’s around $0.10 per query. Run that same document ten times a day across thousands of users, and real operational costs accumulate fast — before you’ve written a single line of business logic.
How Prompt Caching Changes the Math
Prompt caching stores the processed KV cache of static content so subsequent calls reuse it without reprocessing. Anthropic cuts cached input token costs by 90% — that same 40,000-token document costs roughly $0.01 per re-query once cached. OpenAI’s automatic caching triggers above a 1,024-token stable prefix threshold and discounts cached tokens at 50%.
The catch most tutorials skip: cache write tokens on Claude cost roughly 25% above base price because the model computes and stores the KV cache upfront. The math only works when your cache hit rate offsets that write premium.
A low-traffic application with requests spaced ten minutes apart will almost never hit a warm cache — and will actually pay more than uncached pricing. The full caching documentation covers TTL options, cache breakpoint placement, and the workspace-level isolation change from February 2026.
The Silent Tokenizer Tax in Opus 4.7
One more factor that determines cost: the Opus 4.7 tokenizer generates up to 35% more tokens for the same input text compared to previous Claude models. Per-token prices held steady, but teams migrating from Claude 4.6 saw effective cost increases without changing a single line of prompt code. That’s the kind of tokenizer behavior that only surfaces in production.
Input and Output Tokens: Why They’re Priced Differently
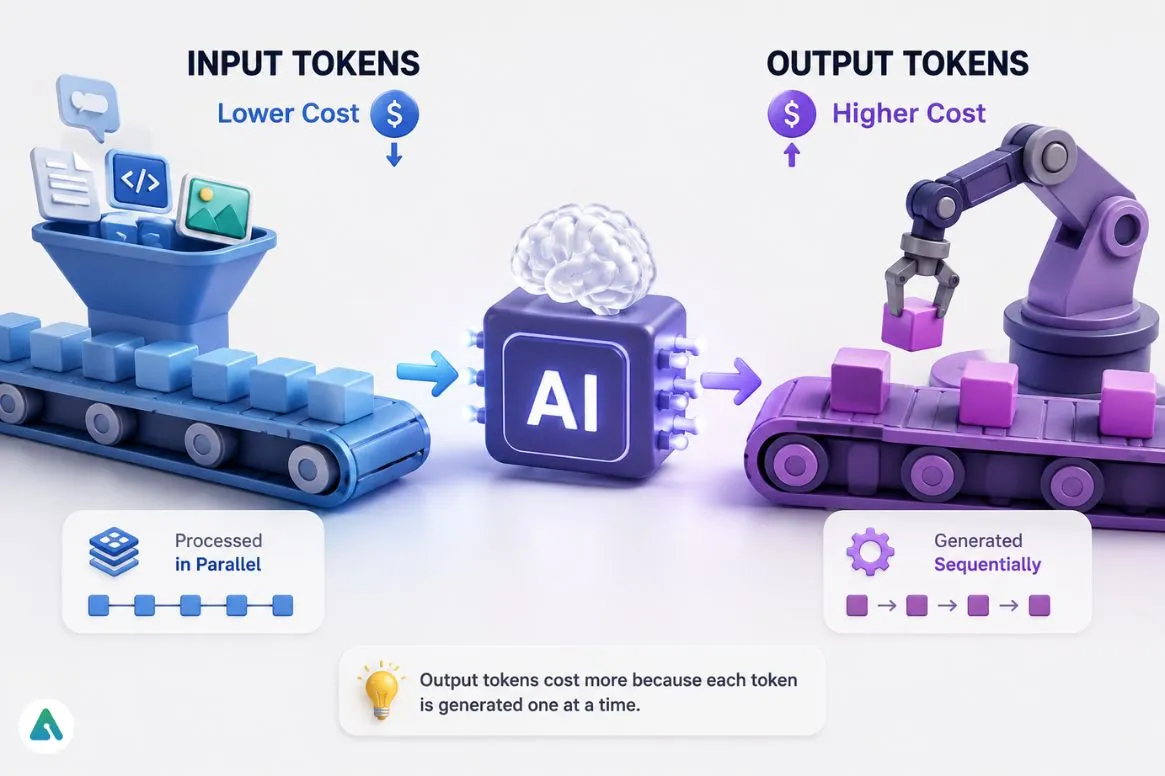
Every AI provider splits billing into two categories, and the split reflects real computational differences.
Input tokens cover everything sent to the model — your prompt, conversation history, system instructions, uploaded files, and retrieved context from RAG pipelines. Processing this content runs at a fixed cost per token.
Output tokens are what the model generates in response. Generating text is fundamentally more expensive than processing it. The model computes each token in sequence, sampling from a probability distribution over its entire vocabulary at every step — you can’t parallelize generation the way you can parallelize input processing.
Think of it this way: input tokens are raw materials arriving on a conveyor belt, and output tokens are finished products assembled one piece at a time. The assembly line costs more per unit than the conveyor belt.
“Be concise” in your system prompt has real cost implications. It reduces output token count — the more expensive half of every API call.
Context Windows: The Model’s Working Memory
A context window is the maximum number of tokens a model holds in working memory during a single inference call. That includes conversation history, system instructions, retrieved documents, and the model’s own previous responses.
Context sizes have grown dramatically. Current flagship models in 2026 support 128K to 2 million tokens — Gemini 2.5 reaches a 2-million-token context window, enough to process entire research paper collections or large codebases in a single pass.
The “Lost in the Middle” Problem
Capacity does not equal processing accuracy. Research consistently shows a U-shaped attention curve across production models: accuracy is highest at the exact start and end of a context window, but drops in the middle.
Key finding: The “Lost in the Middle” study by Liu et al. (Stanford University / UC Berkeley) documented this U-shaped pattern across GPT and Claude models — proving that larger context windows expand capacity but don’t guarantee uniform retrieval quality.
The maximum number of tokens a model can process tells you about its capacity. It says nothing about whether it retrieves everything in that space equally well. Retrieval quality and context size are separate problems — treating them as equivalent is one of the more common mistakes in production AI design.
How Modern Models Tokenize Images, Audio, and Video
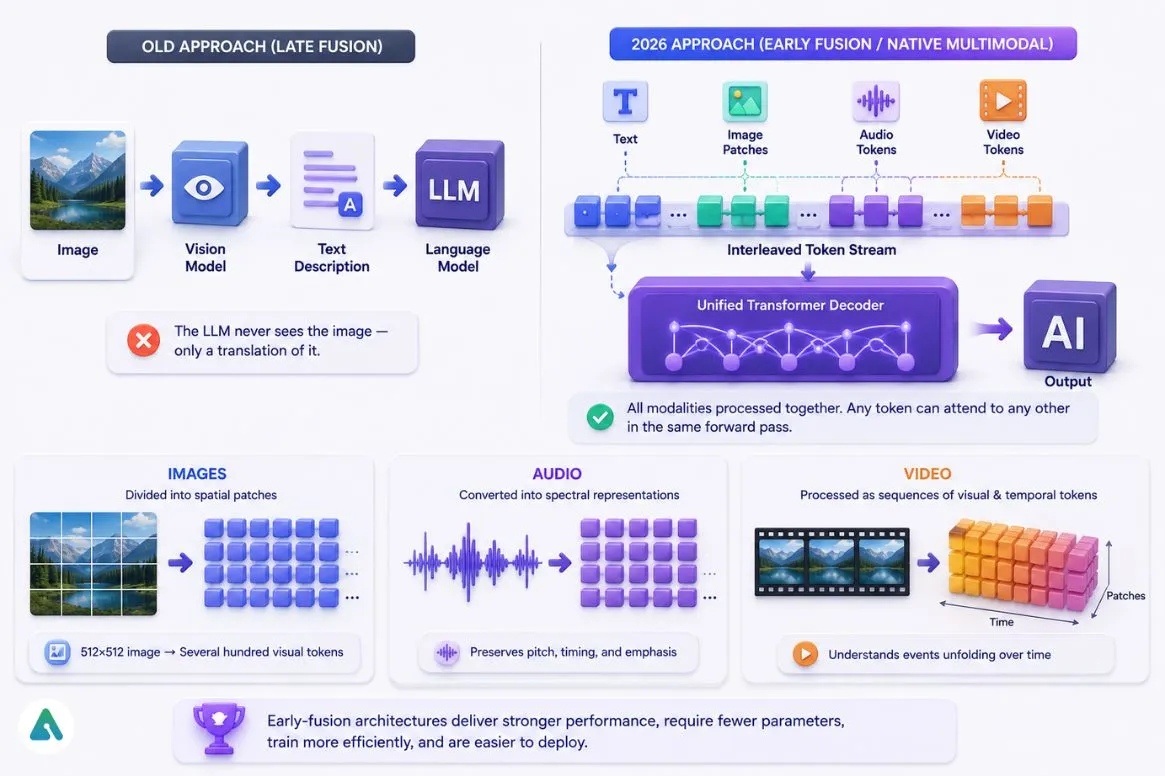
In 2026, tokens aren’t a text-only concept. Multimodal AI services process images, audio, and video through the same token-based architecture.
The old approach (late fusion):
- A separate vision model processes the image
- Converts the result into a text description
- That description feeds into the language model
- The LLM never sees the image — only a translation of it
The 2026 approach (early fusion / native multimodal):
- All modalities — text, image patches, audio, video — cast into a single interleaved token stream
- Image and audio data are embedded and processed through a unified transformer decoder
- Attention mechanisms relate any text token to any image patch directly, in the same forward pass
Research on early-fusion architectures shows stronger performance at lower parameter counts, more efficient training, and simpler deployment compared to late-fusion alternatives.
How each modality tokenizes:
- Images: Divided into spatial patches (small rectangular regions), each converted into a visual token vector. A 512×512 image generates several hundred visual tokens.
- Audio: Converted into spectral representations that preserve pitch, timing, and emphasis — not just transcribed text.
- Video: Processed as sequences of visual and temporal tokens that let the model reason about events unfolding over time.
How Developers Control Token Usage
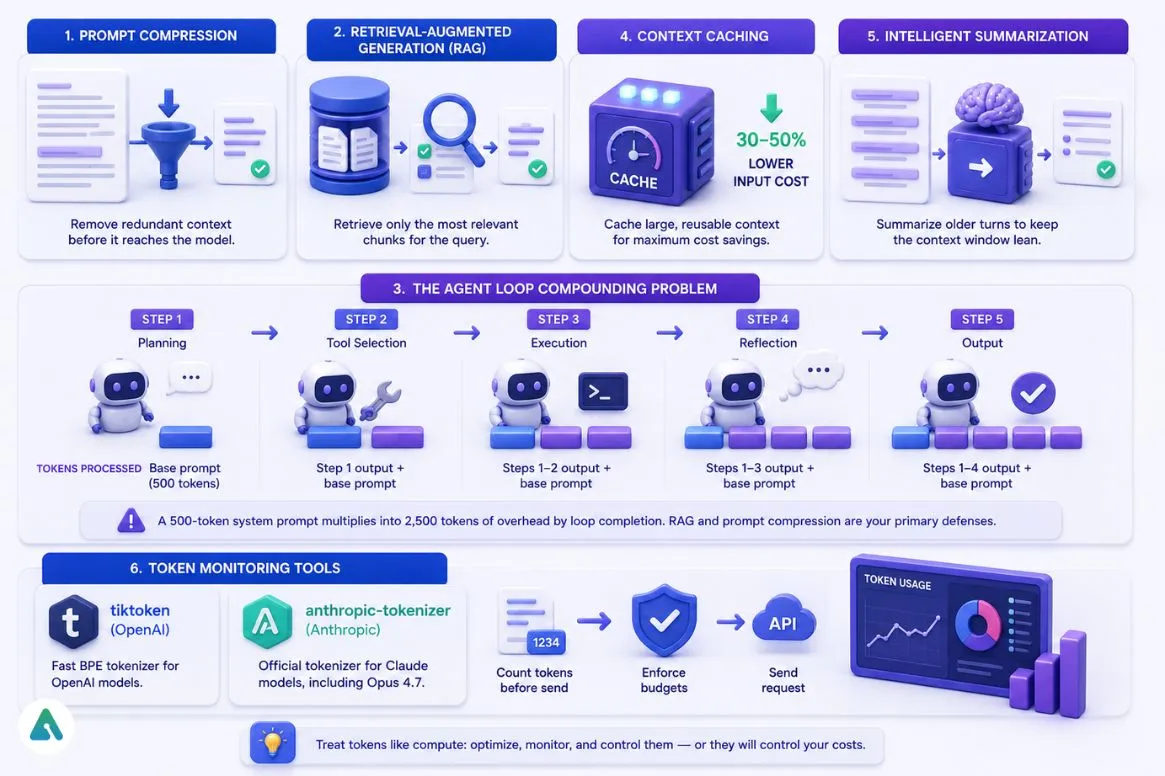
Experienced teams treat token usage as a resource to optimize, not just a billing line to monitor.
Prompt Compression
Strips redundant context before it reaches the model — removing filler language, compressing multi-turn histories into summaries, and cutting boilerplate that doesn’t change between requests.
Retrieval-Augmented Generation (RAG)
Instead of loading an entire knowledge base into the context, a retrieval system identifies the specific chunks most relevant to a query and sends only those. In multi-step AI orchestration pipelines — where multiple agents pass context between each other — RAG prevents token budgets from compounding out of control across each handoff.
The Agent Loop Compounding Problem
This is where token costs blindside most teams. When an autonomous agent runs a 5-step reasoning loop — planning, tool selection, execution, reflection, and output — it doesn’t just pay for the final response.
It pays a compounding tax on the entire conversation history at every single step:
| Agent Step | Tokens Processed |
|---|---|
| Step 1 | Base prompt (500 tokens) |
| Step 2 | Step 1 output + base prompt |
| Step 3 | Steps 1–2 output + base prompt |
| Step 4 | Steps 1–3 output + base prompt |
| Step 5 | Steps 1–4 output + base prompt |
A 500-token system prompt that looks negligible at step 1 quietly multiplies into 2,500 tokens of overhead by loop completion. RAG and prompt compression are the primary defenses against this accumulation.
Context Caching
Delivers the highest ROI for workloads that repeatedly process the same large documents or system prompts. Done well, caching cuts input-token cost by 30 to 50% on agent loops and RAG pipelines. Done poorly — because of TTL mismatches or dynamic content inside cached blocks — it increases costs with no benefit.
Intelligent Summarization
Compresses older conversation turns into concise summaries before they scroll out of the context window. Essential narrative thread preserved, full token-by-token retention avoided.
Token Monitoring Tools
Tracking token usage in production requires proper instrumentation. Two widely used open-source libraries:
- tiktoken (OpenAI) — Fast BPE tokenizer for OpenAI models. Let’s developers count tokens before sending a request, enabling budget enforcement at the application layer.
- anthropic-tokenizer — Anthropic’s official tokenizer library for accurate token counting against Claude models, including Opus 4.7’s updated vocabulary.
Both libraries integrate into pre-send validation layers, so teams catch expensive prompts before they hit the API rather than after the invoice arrives.
The 2026 Tokenizer Generation: Legacy vs. Modern
Every tokenizer operates from a vocabulary dictionary — a fixed list of token fragments the model recognizes as single units. Larger vocabularies mean more patterns compressed into a single token, which means fewer tokens per document, lower costs, and better multilingual support.
| Core Modality Feature | Legacy Text Tokenizers (Pre-2024) | Modern Multimodal Engines (2026) |
|---|---|---|
| Vocabulary bounds | ~50,000 discrete token entries | 100,000–200,000 multi-token arrays |
| Code processing | Poor — heavy syntax fragmentation | High — pre-merged common logic strings |
| Multilingual support | English-optimized, other languages fragment | Balanced across major language families |
| Words per 1,000 tokens | ~750 words (English) | ~800–850 words (English) |
| Multimodal input | None — required separate late-fusion pipeline | Native patch processing via interleaved streams |
| Math/notation | Heavy fragmentation | Improved compression for common notation |
The rule of thumb — 1,000 tokens equals roughly 750 words — comes from older tokenizer generations. Don’t assume parity across models, or even across generations of the same model family. Anthropic’s pricing page explicitly notes that Opus 4.7 and later use a new tokenizer that may use up to 35% more tokens for the same text compared to earlier Claude models.
Why Token Economics Matter Beyond Engineering
Understanding tokens matters well beyond developer teams now.
Content strategists building AI-assisted pipelines need to know why a detailed system prompt determines cost differently from a short conversational message.
Product managers setting usage budgets need to understand why a feature that processes PDFs has fundamentally different economics than one generating short responses.
Anyone evaluating AI services needs to compare tokenizer efficiency, not just per-token rates — a model with a more efficient tokenizer that costs the same per token is actually cheaper for identical content.
Tokens sit at the center of everything: what a model can remember, how much it costs to run, how efficiently it handles different content types, and how reliably it retrieves information from long contexts.
Frequently Asked Questions
Q. What are tokens in AI in simple terms?
Tokens are the small units that AI models use to read and generate language. Think of them as the alphabet of AI — not letters, not full words, but reusable fragments that every model processes mathematically before producing any output.
Q. Is one AI token equal to one word?
No. Common words are usually one token; rare or technical words split into several. Modern 2026 tokenizers convert standard English at roughly 800–850 words per 1,000 tokens, but code and multilingual content shift that ratio significantly.
Q. What are 100 tokens in AI?
In standard English prose, 100 AI tokens equal roughly 80 to 85 words. For technical data — code, JSON, or URLs — 100 tokens compress much less efficiently, often translating to fewer than 40–50 words due to character-level fragmentation.
Q. How much do 100 tokens cost in 2026?
At current premium model rates, 100 input tokens cost approximately $0.00015–$0.0003 depending on provider and tier. Output tokens run roughly 3–5x higher per token. With prompt caching active, cached input reads drop to roughly 10% of standard input cost on Anthropic’s platform.
Q. Why do AI companies charge by tokens rather than words or pages?
Tokens measure the actual computational work a model performs. A page of Python code and a page of prose consume very different token counts — words and pages don’t capture that variation in processing load.
Q. What is the difference between input and output tokens?
Input tokens are everything sent to the model — prompts, history, files, instructions. Output tokens are what the model generates. Output tokens cost more because generating text requires sequential, non-parallelizable computation at each step.
Q. What is a context window?
The maximum number of tokens a model processes at once — its working memory. A 128K context window holds roughly 100,000+ words of combined input and output. Larger windows expand capacity but don’t guarantee uniform retrieval from all positions.
Q. Do images and audio use tokens?
Yes. Modern multimodal models convert image patches, audio patterns, and video frames into token-like vectors interleaved directly into the same token stream as text — processed through the same transformer architecture in a single forward pass.
Q. What is Byte-Pair Encoding?
A compression technique for building tokenizer vocabularies via character-level merging. BPE repeatedly merges frequently co-occurring character pairs into single tokens, creating a vocabulary where common patterns compress efficiently, and rare content splits into multiple tokens.
Q. What is prompt caching, and how does it reduce token costs?
Prompt caching stores processed KV-cache versions of static prompt content so subsequent calls reuse it without reprocessing. Anthropic charges a write premium but reduces cache reads by 90%. OpenAI’s automatic caching discounts cached tokens at 50%.
Q. What tools can I use to count tokens before sending a request? tiktoken
(OpenAI) The anthropic-tokenizer library is one of the two most widely used open-source options. Both let developers count tokens at the application layer before the API call, enabling cost enforcement before the invoice arrives.
The Bridge Between Language and Computation
Every capability in modern AI — answering questions, analyzing legal contracts, understanding video — starts with the same step: converting input into tokens. The transformer architecture, the attention mechanisms, the reasoning chains, the multimodal processing — all of it operates on token sequences.
The next time a context limit truncates a document, an API bill surprises you, or a model loses track of something from earlier in the conversation — the explanation almost certainly traces back to token mechanics.
Related: AI Transformation Is a Governance Problem (Not Tech) — 2026 Truth
| Disclaimer: This article is intended for educational and informational purposes only. AI models, token limits, pricing, and platform features evolve quickly, so some details may change over time. While we’ve made every effort to ensure accuracy, we recommend always double-checking the latest information with the official documentation of the AI provider you’re using. |
